LLM 大语言模型发展及关键资源
什么是 LLM?
大型语言模型 (Large Language Models, LLMs) 是近年来自然语言处理(NLP)领域的重要进展,是指规模相当大(如包含数百亿到数千亿参数)的预训练语言模型(PLM)。这些模型被训练以预测文本中的下一个词。通过这种训练,它们学习了大量的语言、事实、逻辑和某种程度的推理能力。
自然语言处理(NLP)的发展经历了多个阶段:
- 早期阶段 (1950s-1980s):在 NLP 的早期,专家系统和硬编码的语法规则主导了领域,人们主要依靠手工定义的规则进行句法分析和早期的机器翻译实验。
- 统计时代 (1980s-2000s):随着统计学的崛起,NLP 开始采用像隐马尔可夫模型、条件随机场和基于短语的统计机器翻译等统计方法,同时 N-gram 语言模型也得到了广泛应用。
- 初级深度学习时代 (2000s-2013):在这一时期,研究者们开始初步探索如何使用前馈和递归神经网络在NLP中学习词的表示,尽管这些方法当时还没有获得广泛的关注。
- 深度学习时代 (2013 年之后):2013 年的 Word2Vec 标志着深度学习在NLP 的广泛应用。之后,LSTM、GRU 和特别是 Transformer 架构引领了一个新时代,预训练模型如 ELMo、GPT 和 BERT 开始在各种NLP任务中设立新的标准。
- 词嵌入:Word2Vec (by Google) 和 GloVe (by Stanford) 是两种著名的词嵌入技术,用于为词汇生成密集的向量表示。
- 循环神经网络 (RNNs) 和长短时记忆网络 (LSTMs):这些模型被用于序列到序列的任务,例如机器翻译和文本生成。
- 卷积神经网络 (CNNs):虽然 CNNs 主要用于图像处理,但它们也被应用于 NLP 任务,如文档分类和情感分析。
- 在深度学习方法流行之后,Seq2Seq 模型和注意力机制开始在机器翻译等任务中取得重要的地位。
LLMs 通常使用两步方法进行训练。首先,它们会在大量的文本数据上进行预训练,学习语言结构、事实和一般知识。然后,它们可以在特定的任务或数据集上进行微调,以适应特定的应用或需求。这些模型被训练成了“宽泛”的知识存储库,能够处理多种不同的任务,而不需要为每个特定任务从零开始训练。因此,许多 NLP 特定任务不再具备单独研究的价值。
2013 年是一个重要转折点,Mikolov 等人提出 Word2Vec,这是一种预训练词嵌入embedding 技术,它可以生成词的密集向量表示,这些表示能够捕获丰富的语义和语法信息。词向量是将词表示为固定大小的向量,相似的词在向量空间中距离更相近。 Word2Vec 的成功推动了深度学习在 NLP 中的应用,并催生了后续的预训练模型,如 ELMo、GPT和BERT。
2017年,Vaswani 等人在论文《Attention Is All You Need》中提出了一个叫做 Transformer 的深度学习模型架构,它为自然语言处理和其他序列到序列的任务带来了革命性的变革。Transformer 的主要特点是其自注意力(self-attention)机制,该机制允许模型在不依赖循环或卷积的前提下,对输入序列中的所有位置进行并行计算。 NLP 中不同的子领域,其特征抽取器都逐渐从 LSTM/CNN 统一到 Transformer 上。这种架构的一个关键优势是其并行计算的能力,与 RNN(循环神经网络)相比,它可以更有效地在 GPU 上进行训练。
2018年,Google 发布了 Bert,引起了广泛关注,因为它在各种自然语言处理(NLP)任务上都取得了突破性的性能。与之前的预训练模型(如GPT)相比,BERT的一个关键特点是它的双向性。在预训练阶段,BERT通过随机遮盖输入句子中的某些词汇并尝试预测这些词汇来训练,这允许模型同时考虑一个词的左边和右边的上下文。Bert 证明了双向语言模型对于很多NLP理解类任务,效果比自回归这种单向语言模型效果更好。
2020年5月,OpenAI 发布了 GPT-3,GPT-3 是当时世界上最大的语言模型,拥有 1750 亿的参数。其巨大的规模使其能够执行多种复杂任务,经常无需任何任务特定的微调。GPT 走的是生成模式的自回归语言模型路线。GPT-3 能够进行零次微调 (Zero-shot learning)、一次微调 (One-shot learning) 和多次微调 (Few-shot learning)。这意味着模型可以在给定一个或没有示例的情况下理解和执行新任务。
可以说,自 2018 年以来, Bert、GPT 这两个大型预训练模型的出现,彻底开启了 LLM 领域研究的新范式,各大公司和研究机构纷纷开始训练和发布自己的大语言模型。
2019 年至今,大语言模型发布的时间线:
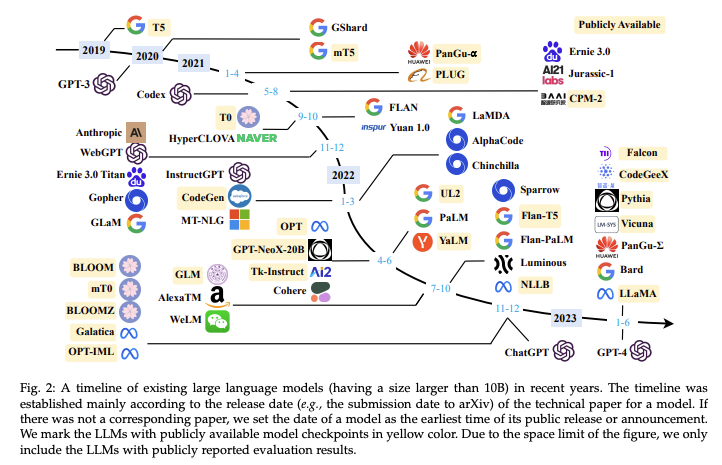
图片来源:W. X. Zhao等, 《A Survey of Large Language Models》
想要更多了解 LLM 的底层原理和训练过程,可以参考我整理的八篇必读论文。
LLM 必读论文
- [1]T. Mikolov, K. Chen, G. Corrado和J. Dean, 《Efficient Estimation of Word Representations in Vector Space》. arXiv, 2013年9月6日. doi: 10.48550/arXiv.1301.3781.
- [2]T. Mikolov, I. Sutskever, K. Chen, G. Corrado和J. Dean, 《Distributed Representations of Words and Phrases and their Compositionality》. arXiv, 2013年10月16日. doi: 10.48550/arXiv.1310.4546.
- [3]A. Vaswani等, 《Attention Is All You Need》. arXiv, 2017年12月5日. doi: 10.48550/arXiv.1706.03762.
- [4]J. Devlin, M.-W. Chang, K. Lee和K. Toutanova, 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》. arXiv, 2018年10月. doi: 10.48550/arXiv.1810.04805.
- [5]T. B. Brown等, 《Language Models are Few-Shot Learners》. arXiv, 2020年7月22日. doi: 10.48550/arXiv.2005.14165.
- [6]J. Wei等, 《Finetuned Language Models Are Zero-Shot Learners》. arXiv, 2022年2月8日. doi: 10.48550/arXiv.2109.01652.
- [7]L. Ouyang等, 《Training language models to follow instructions with human feedback》. arXiv, 2022年3月4日. doi: 10.48550/arXiv.2203.02155.
- [8]W. X. Zhao等, 《A Survey of Large Language Models》. arXiv, 2023年6月29日. doi: 10.48550/arXiv.2303.18223.
其中,前两篇论文是自监督学习 Self-Supervised Learning 方法的起源,即 word2vec 中的 CBOW 方法。第三篇 Transformer 开启了一种新的训练思路。第四篇 Bert 模型证明了自监督学习的效果。第五篇是尝试 few-shot 少数提示的微调方法。第六篇 instruction tuning 开启了有监督的微调方法。第七篇 OpenAI 在instructGPT 中使用了 RLHF 人类对齐强化学习。
最后一篇是一篇大语言模型的综述论文,介绍了 LLMs 的背景、主要发现和主流技术,重点关注 LLM 的四个主要方面,即预训练、微调、效用和能力评估。此外,这篇综述论文还总结了开发 LLMs 的可用资源,并讨论了未来发展方向的遗留问题。
LLM 有什么用?
LLM (Large Language Model) 的应用场景多种多样,它们的能力已被利用于各种行业和场合。以下是一些主要的应用场景:
- 内容创作: LLM 可以帮助记者、作家、和内容创作者生成文章、博客、和其他写作材料的草稿或想法。
- 教育: LLM 可以用作教育工具,为学生提供写作、编程或其他学术主题的反馈和建议。
- 编程辅助: 在软件开发中,LLM 可以提供代码补全、代码建议或修复代码中的错误。
- 客服与支持: LLM 可以作为客服机器人,为用户提供实时的查询回复和技术支持。
- 娱乐与游戏: 在游戏和虚拟世界中,LLM 可以为角色生成对话,增强玩家的沉浸体验。
- 搜索与推荐系统: LLM 可以增强搜索引擎的能力,提供更加相关的搜索结果或内容推荐。
- 市场营销: 在广告和营销领域,LLM 可以生成广告文案或帮助进行市场趋势分析。
- 法律助理: LLM 可以帮助律师检索法律文件,提供相关的案例或法规信息。
- 医疗咨询: 虽然不能替代医生,但LLM 可以为患者提供基础的健康信息和建议。
- 研究: 在科研领域,LLM 可以帮助研究者快速查找文献、生成研究摘要或提供其他相关的建议。
- 多语言翻译: 虽然专用的翻译模型可能更准确,但LLM 也能进行实时的多语言翻译。
- 问答系统: LLM 可以在企业内部或公共平台上作为问答系统,回答用户的各种问题。
- 社交媒体监控: LLM 可以分析社交媒体上的内容,帮助企业或政府机构了解公众的情感和反应。
这些只是LLM的部分应用场景。随着技术的进步,其应用可能会进一步拓展和深化。但与此同时,也需要注意到LLM的使用可能带来的伦理和社会问题,如偏见、误导和隐私问题等。
大型语言模型 (LLM) 如 GPT-3 和 BERT 在一些应用场景中表现出色,而在其他场景中可能存在一些局限性。以下是 LLM 最擅长和最不擅长的应用场景: LLM 最擅长的应用场景:
- 文本生成:LLM 非常适合生成连贯的、人类般的文本,无论是完整的文章、故事、诗歌或其他写作形式。
- 文本补全与纠正:LLM 可以有效地补全断句、纠正文本中的语法和拼写错误。
- 问答系统:对于许多常见的问题,LLM 可以提供准确和详细的答案。
- 编码辅助:LLM 能够提供代码建议、代码补全以及识别一些代码错误。
- 语言翻译:尽管专业的翻译系统可能更优,但 LLM 在基本的翻译任务上表现也相当可靠。
- 知识查找:对于其在训练数据中所涵盖的知识,LLM 可以作为一个有效的查询工具。 LLM 最不擅长的应用场景:
- 特定领域的深度专家知识:对于高度专业化或需要最新信息的查询,LLM 可能无法提供最准确的答案。
- 逻辑和批判性思维:虽然 LLM 可以生成连贯的文本,但它可能缺乏真正的批判性思维和深度逻辑分析。
- 创新和原创性:LLM 主要基于它的训练数据生成输出,它可能不会产生真正的创新或原创的想法。
- 处理有偏见的信息:LLM 可能从其训练数据中继承偏见,并在输出中反映这些偏见,这可能导致不准确或有害的信息。
- 实时事件和最新数据:LLM 的知识基于其最后的训练数据,所以对于最近的事件或数据它可能不知情。
- 高度互动或需要持续关注的任务:LLM 无法持续跟踪和理解长时间、多轮次的互动,可能导致上下文丢失。
LLM 重要研究机构
- 美国
- Stanford CRFM:https://crfm.stanford.edu/
- MIT CSAIL:https://www.csail.mit.edu/
- Allen Institute for AI:https://allenai.org/
- Berkeley AI research:https://bair.berkeley.edu/
- Michigan AI Lab:https://ai.engin.umich.edu/
- EleutherAI:https://www.eleuther.ai/about
- CarperAI:https://carper.ai/
- AI21labs:https://www.ai21.com/
- MIT-IBM AI lab:https://mitibmwatsonailab.mit.edu/
- Intel labs:https://www.intel.com/content/www/us/en/research/ai.html
- 欧洲
- The Alan Turing Institute:https://www.turing.ac.uk/about-us
- Cambridge NLP:https://www.cst.cam.ac.uk/research/themes/natural-language-processing
- BigScience:https://bigscience.huggingface.co/
- 加拿大
- Vector Institute AI:https://vectorinstitute.ai/
- Ethics of AI Lab:https://ethics.utoronto.ca/
- 中国
- Zhipu AI:https://www.zhipuai.cn/
- KEG:http://keg.cs.tsinghua.edu.cn/
LLM 关键公司
- 美国
- OpenAI:https://openai.com/
- Anthropic:https://www.anthropic.com/
- Cohere:https://cohere.com/
- Google AI:https://ai.google/
- Meta AI:https://ai.meta.com/
- HuggingFace:https://huggingface.co/
- Nvidia:https://research.nvidia.com/research-area/machine-learning-artificial-intelligence
- Microsoft:https://turing.microsoft.com/
- Databricks:https://www.databricks.com/
- Together.AI:https://together.ai/
- Weights & Biases:https://wandb.ai/site
- Stabilty.ai:https://stability.ai/
- AWS:https://aws.amazon.com/cn/ai/
- Adobe:https://www.adobe.com/sensei/generative-ai/firefly.html
- Scale.ai:https://scale.com/about
- Saleforce AI Research:https://www.salesforceairesearch.com/
- Apple:https://www.apple.com/careers/us/machine-learning-and-ai.html
- Thomson Reuters Labs:https://www.thomsonreuters.com/en/artificial-intelligence/research.html
- Inflection AI:https://inflection.ai/
- Character AI:https://beta.character.ai/
- Adept:https://www.adept.ai/
LLM 核心人物
- Geoffrey Hinton
- Yann LeCun
- Yoshua Bengio
- Ilya Sutskever
- Greg Brockman
- Alec Radford
- Wojciech Zaremba
- Lukasz Kaiser
- Tomer Kaftan
- Barret Zoph
- Jeffery Wu
- Sandhini Agarwal
- Gretchen Krueger
- Christopher Hesse
- Long Ouyang
- Ryan Lowe
- Nick Ryder
- Shane Gu
- Clemens Winter
- Benjamin Chess
- Shantanu Jain
- Jan Leike
- John Schulman
- Jacob Hilton
- Jacob Devlin
- Tim Salimans
- Jakob Uszkoreit
- Rewon Child
- Joe Fenton
- Maarten Bosma
- Dario Amodei
- Tom B. Brown
- Christopher Olah
- Jared Clark
- Sam McCandlish
- Benjamin Mann
- Amanda Askell
- Tom Henighan
- Ashish Vaswani
- Niki Parmar
- David Luan
- Noam Shazeer
- Daniel De Freitas
- Aidan Gomez
参考资料
- W. X. Zhao等, 《A Survey of Large Language Models》. arXiv, 2023年6月29日. doi: 10.48550/arXiv.2303.18223.
- 通向AGI之路:大型语言模型(LLM)技术精要-张俊林
有关 LLM 优质信息源的持续更新,请关注我的 GitHub 仓库:https://github.com/zhengxixuan/awesome-LLM-keynotes